Что такое КБЖУ . Книга ЗОЖника
Загадочная аббревиатура КБЖУ – это матрица, через которую можно смотреть на любую еду. КБЖУ – это калории, белки, жиры и углеводы.
Важность того, что кроется за первой буквой, мы уже обсудили – это обозначение количества энергии, которая содержится в пище. В целом закон энергетического баланса (съел больше нормы калорийности – потолстел, съел меньше – похудел) работает независимо от того, как мы распределяем наши БЖУ. И оценка калорийности пищи – первый и самый важный шаг в отношении любой еды, если ваша цель – изменить массу тела.
Следующий по важности момент – это оценка количества в нашем рационе трех макронутриентов: белков, жиров и углеводов, без которых мы не можем жить долго и здорово. Каждый из этих нутриентов имеет важнейшее значение для самых разных процессов в нашем теле.
Например, в готовой овсянке на воде больше всего углеводов (15 % веса), совсем немного белка (около 3 %) и меньше 2 % веса – жиры. В стейке – в основном белки (около 23 % веса), жиры (около 12–15 %) и вообще нет углеводов.
В какой пропорции нам нужны белки, жиры и углеводы
Идеального и универсального соотношения белков, жиров и углеводов в питании не существует, более того, как вы уже узнали из этой главы, решающее значение для изменения веса имеет количество, а не качество поступающих с пищей калорий.
Тем не менее несколько авторитетных организаций предоставляют конкретные рекомендации расчета пропорции БЖУ.
Рекомендации по соотношению макронутриентов от Всемирной организации здравоохранения (ВОЗ)
1. Углеводам необходимо отводить около 50–55 % калорийности пищи. Большая их часть должна поступать из круп (коричневый рис, киноа, гречневая крупа, овсяные хлопья, макароны из твердых сортов пшеницы) и цельнозернового хлеба, а также фруктов, овощей и бобовых. Свободным (добавленным) сахарам при этом рекомендуется отводить менее 10 % общей калорийности рациона[2].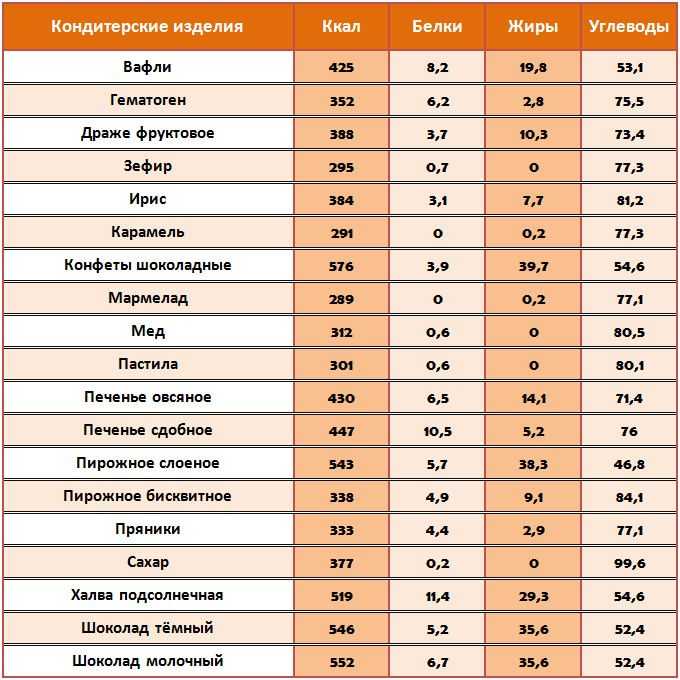
2. Жиры должны составлять около 30 % общей калорийности, при этом большая их часть должна поступать из ненасыщенных жиров. В эту группу входят жирная рыба, авокадо, орехи, семечки, льняное, рапсовое, оливковое масла. Насыщенным жирам (сыры, жирное мясо, сливочное масло, жирные молочные продукты) рекомендуется отводить до 10 % общей калорийности пищи.
3. Белки должны занимать в рационе около 15–20 % общей калорийности. Лучшие источники: рыба, постная птица, говядина и свинина, молочные продукты с низким процентом жирности, яйца.
Перевести калорийность в граммы легко, зная, что в каждом грамме углеводов и белков – по 4,1 ккал, а в 1 грамме жира – 9,3 ккал. Соответственно, если ваша дневная норма составляет 2000 ккал, то рекомендуемая доля в 55 % углеводов соответствует 1100 ккал, или 1100/4,1 = 268 г углеводов в сутки.
Сколько граммов БЖУ надо есть по рекомендации ВОЗ
Приведенные выше данные рассчитаны на среднестатистического человека, который не стремится к спортивным достижениям.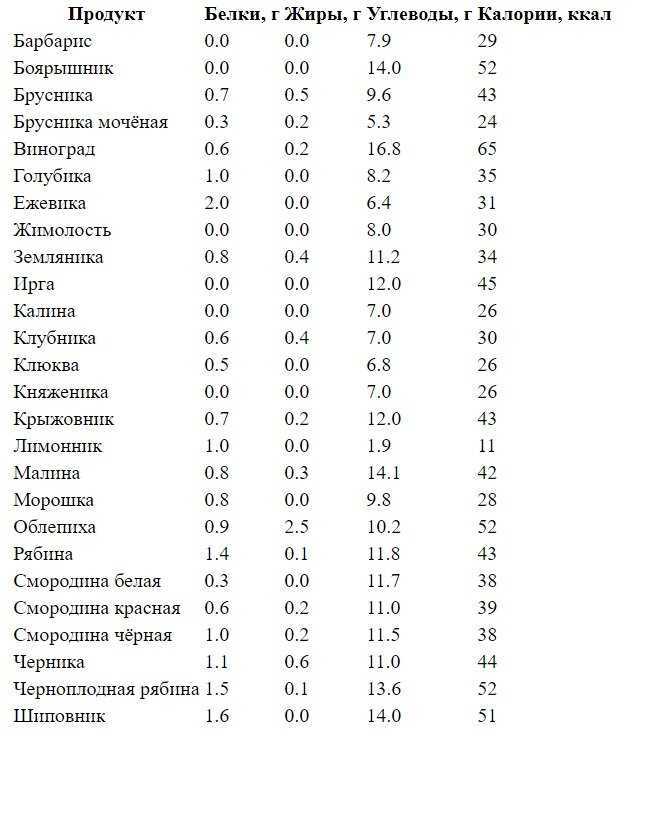 В зависимости от состояния здоровья, целей (похудеть, набрать мышечную массу, поддерживать вес, увеличить работоспособность при физических нагрузках), вида и интенсивности тренировок соотношение белков, жиров и углеводов может меняться.
В зависимости от состояния здоровья, целей (похудеть, набрать мышечную массу, поддерживать вес, увеличить работоспособность при физических нагрузках), вида и интенсивности тренировок соотношение белков, жиров и углеводов может меняться.
Соотношение макронутриентов для тренирующихся
Рекомендуемое соотношение макронутриентов для подвергающихся физическим нагрузкам людей было впервые представлено в 2005 году Институтом медицины США[3].
Специалисты этой организации предлагают тренирующимся такое соотношение:
• углеводы – 45–65 %;
• белки – 10–35 %;
• жиры – 20–35 %.
Как видите, диапазоны широки и в целом рекомендации перекликаются с тем, что советует ВОЗ.
Обязательно ли есть меньше углеводов, чтобы похудеть
Если вы внимательно прочитали про закон энергетического баланса, то сами, очевидно, ответите: конечно же, не обязательно, ведь решающее значение имеет общая калорийность, а не соотношение между белками, жирами и углеводами.
Мы добавим аргументов: в 2009 году в The New England Journal of Medicine было представлено исследование[4], в котором приняли участие 811 человек с ожирением. Испытуемых разделили на четыре группы. У всех был одинаковый дефицит калорий, но разная пропорция макронутриентов.
Соотношение БЖУ для разных групп, %
Через полгода все участники эксперимента в среднем потеряли по 6 кг независимо от пропорции нутриентов – разная доля углеводов в рационе не оказала значительного эффекта на похудение.
Это лишь одно из десятков исследований, в выводах к которому ученые говорят: снижение калорийности приводит к потере веса независимо от того, сколько именно углеводов, белков и жиров было в рационе.
Поэтому не бойтесь углеводов! Они не мешают нам снижать вес и очень важны для нашего организма по причинам, о которых мы расскажем в отдельной главе.
Данный текст является ознакомительным фрагментом.
Как правильно читать этикетки продуктов
По сути этикетка — это «паспорт» продукта. Когда и где он «родился», кто поучаствовал в его создании, из чего состоит, сколько полезных или не очень веществ содержит. Всё это зашифровано производителем и нужно только уметь разгадать шифр.
На территории Российской Федерации действует технический регламент Таможенного союза ТР ТС 022/2011, где подробно перечислены требования к маркировке продуктов питания. Если производитель эти требования не соблюдает, это говорит либо о непрофессионализме технологов, либо о сознательной попытке ввести в заблуждение потребителя.
В информации на этикетке можно потеряться. Вот на что нужно в первую очередь обращать внимание:
Наименование продукта
Это не то же самое, что и название. Название используют в маркетинговых целях и оно не всегда отражает состав товара. Например, «Икра Царская» — это не настоящая икра, а её дешёвый аналог. Её производят из желе, полученного из морских водорослей. Сливочное масло может оказаться спредом, а творог — творожным продуктом. Всё это всегда указано на упаковке, просто гораздо более мелкими буквами и в неочевидном месте — с краю и подальше от глаз.
Например, «Икра Царская» — это не настоящая икра, а её дешёвый аналог. Её производят из желе, полученного из морских водорослей. Сливочное масло может оказаться спредом, а творог — творожным продуктом. Всё это всегда указано на упаковке, просто гораздо более мелкими буквами и в неочевидном месте — с краю и подальше от глаз.
Состав продукта
Запомните: ингредиенты всегда указываются в порядке убывания. То есть на первом месте стоит то, чего больше всего содержится. Допустим, в составе сосисок на первом месте должно быть мясо, а не соя.
Далее указываются дополнительные ингредиенты. Они придают продукту нужную текстуру, усиливают вкус и продлевают срок хранения. Как правило, это загустители (например, желатин или крахмал), эмульгаторы (соевый лецитин или яичный порошок), консерванты (часто это соль и сахар), ароматизаторы и красители. Все они могут быть натуральными и синтетическими. Синтетический не равно вредный.
Буква «Е» в составе продукта, которую привыкли демонизировать, на самом деле не так страшна. Наличие такой маркировки говорит о том, что вещество было проверено на качество и безопасность и может применяться в установленной дозировке. Среди них есть и натуральные добавки. Например, E 406 — это агар-агар (E 406), который получают из водорослей. А E 440 — пектин, производимый из фруктов. Чтобы вам было легче ориентироваться, что есть что, вот расшифровка. Если числовой код начинается с единицы, это пищевой краситель. С двойки — консерванты, тройки — антиокислители. 4 — это стабилизаторы, 5 — эмульгаторы, а 6 — усилители вкуса и аромата.
Наличие такой маркировки говорит о том, что вещество было проверено на качество и безопасность и может применяться в установленной дозировке. Среди них есть и натуральные добавки. Например, E 406 — это агар-агар (E 406), который получают из водорослей. А E 440 — пектин, производимый из фруктов. Чтобы вам было легче ориентироваться, что есть что, вот расшифровка. Если числовой код начинается с единицы, это пищевой краситель. С двойки — консерванты, тройки — антиокислители. 4 — это стабилизаторы, 5 — эмульгаторы, а 6 — усилители вкуса и аромата.
Срок годности
Срок годности всегда указывается с запасом. Так что теоретически просроченный на 1 день хлеб можно спокойно есть, если он визуально выглядит нормально. Но лучше укладываться в указанные сроки. Также важно понимать, что продукт необходимо правильно хранить, иначе срок годности может сократиться. О том, как правильно хранить различные продукты, можно прочитать в этом материале.
В большинстве случаев быстрее портятся те продукты, которые менее всего обработаны. Увеличить срок хранения можно либо с помощью консервантов, либо посредством ультра-обработки. При ультра-обработке из продукции убираются те вещества, которые могут спровоцировать размножение бактерий. Например, пробиотики или ненасыщенные жирные кислоты. А с этими веществами неизбежно уходит часть полезности. Есть такие продукты можно, но при прочих равных лучше отдать предпочтение альтернативам с более коротким сроком годности. Что относится к ультра-обработанным продуктам? Чипсы, лапша быстрого приготовления, сладкая газировка, шоколадные батончики.
Увеличить срок хранения можно либо с помощью консервантов, либо посредством ультра-обработки. При ультра-обработке из продукции убираются те вещества, которые могут спровоцировать размножение бактерий. Например, пробиотики или ненасыщенные жирные кислоты. А с этими веществами неизбежно уходит часть полезности. Есть такие продукты можно, но при прочих равных лучше отдать предпочтение альтернативам с более коротким сроком годности. Что относится к ультра-обработанным продуктам? Чипсы, лапша быстрого приготовления, сладкая газировка, шоколадные батончики.
Пищевая ценность
На Западе требования к маркировке более строгие, поэтому там помимо стандартного КБЖУ указывается количество соли, сахара, клетчатки и разных видов жиров. У нас такие подробности прописываются на добровольной основе.
Калорийность (или энергетическая ценность) продукта — это то количество энергии, которое выделяется за время его усвоения. И это то, на что в первую очередь обращают внимание. Помимо калорийности на этикетке отмечено количество макронутриентов: белков, жиров и углеводов. Чаще всего значения указываются в расчёте на 100 г продукта, но иногда на порцию. Так бывает с хлопьями для завтрака. Поэтому обязательно смотрите, сколько граммов в порции должно быть, по мнению производителя, и сколько у вас. В зависимости от этого можно высчитать калорийность блюда.
Помимо калорийности на этикетке отмечено количество макронутриентов: белков, жиров и углеводов. Чаще всего значения указываются в расчёте на 100 г продукта, но иногда на порцию. Так бывает с хлопьями для завтрака. Поэтому обязательно смотрите, сколько граммов в порции должно быть, по мнению производителя, и сколько у вас. В зависимости от этого можно высчитать калорийность блюда.
Если в продукт были добавлены витамины или минеральные вещества, их обязательно должны перечислить на этикетке.
Материал упаковки
Во-первых, в соответствии с регламентом Таможенного союза на таре, которая соприкасается с пищевым продуктом, обязательно должен быть указан символ, что материал не токсичен и может использоваться для упаковки пищи.
Во-вторых, обязательна маркировка петлёй Мёбиуса. Эта информация понадобится, если вы сортируете мусор и сдаёте упаковку на переработку. Найдите на этикетке цифру в треугольнике (петле). Цифра — это код идентификации, по которому определяется гипотетическая возможность утилизации упаковки. К сожалению, наличие такого кода не означает, что тару точно можно сдать в пункт приёма вторсырья. Есть не перерабатываемые виды пластика. В России не перерабатывают пластик с кодами 3 и 7, а с кодом 6 всё сложно — его принимают единицы компаний.
К сожалению, наличие такого кода не означает, что тару точно можно сдать в пункт приёма вторсырья. Есть не перерабатываемые виды пластика. В России не перерабатывают пластик с кодами 3 и 7, а с кодом 6 всё сложно — его принимают единицы компаний.
Что можно сделать в данной ситуации? Выбирать продукты в перерабатываемой упаковке или, есть есть возможность, без неё. Например, не покупать овощи на подложке. Она делается из вспененного полистирола, код 6. Купите овощи без упаковки и сложите в свою сумку или пакет. Яйца берите в картонном лотке, а не пластиковом.
стратегий декодирования, которые необходимо знать для генерации ответа | by Vitou Phy
Различие между поиском луча, случайной выборкой, Top-K и Nucleus
Различные методы выборки. Обратите внимание, что в этом примере мы не использовали сильную генеративную модель. Глубокое обучение было развернуто во многих задачах НЛП, таких как перевод, создание подписей к изображениям и диалоговые системы. В машинном переводе он используется для чтения исходного языка (ввод) и создания нужного языка (вывод). Точно так же в диалоговой системе он используется для генерации ответа в зависимости от контекста. Это также известно как генерация естественного языка (NLG).
В машинном переводе он используется для чтения исходного языка (ввод) и создания нужного языка (вывод). Точно так же в диалоговой системе он используется для генерации ответа в зависимости от контекста. Это также известно как генерация естественного языка (NLG).
Модель делится на 2 части: энкодер и декодер. Encoder читает входной текст и возвращает вектор, представляющий этот вход. Затем декодер берет этот вектор и генерирует соответствующий текст.
Рисунок 1: Архитектура кодировщика-декодераЧтобы сгенерировать текст, обычно это делается путем создания одного токена за раз. Без надлежащих методов сгенерированный ответ может быть очень общим и скучным. В этой статье мы рассмотрим следующие стратегии:
- Жадные
- Поиск луча
- Случайная выборка
- Температура
- Выборка Top-K
- Выборка ядра
На каждом временном шаге во время декодирования мы берем вектор (который содержит информацию от одного шага к другому) и применяем его с помощью softmax функция, чтобы преобразовать его в массив вероятности для каждого слова.
Жадный подход
Это самый простой способ. На каждом временном шаге он просто выбирает наиболее вероятный маркер.
Контекст: Попробуйте этот торт. Я испекла его сама.
Оптимальный ответ : У этого торта прекрасный вкус.
Сгенерированный ответ: все в порядке.
Однако такой подход может привести к неоптимальному ответу, как показано в приведенном выше примере. Сгенерированный ответ может быть не самым лучшим ответом. Это связано с тем, что обучающие данные обычно содержат такие примеры, как «Это […]». Поэтому, если мы сгенерируем наиболее вероятный токен за раз, он может вывести «is» вместо «cake».
Лучевой поиск
Исчерпывающий поиск может решить предыдущую проблему, так как он будет искать во всем пространстве. Однако это было бы вычислительно дорого. Предположим, что есть 10 000 словарей, чтобы сгенерировать предложение длиной 10 токенов, это будет (10 000)¹⁰.
Поиск луча может справиться с этой проблемой. На каждом временном шаге он генерирует все возможные токены в списке словарей; затем он выберет лучшие B кандидатов, которые имеют наибольшую вероятность. Эти B-кандидаты перейдут к следующему временному шагу, и процесс повторится. В итоге останется только B кандидатов. Пространство поиска составляет всего (10 000)*B.
Контекст: Попробуйте этот торт. Я испекла его сама.
Ответ A: У этого торта прекрасный вкус.
Ответ Б: Спасибо.
Но иногда выбирает даже более оптимальный вариант (Ответ Б). В данном случае это имеет смысл. Но представьте, что модель любит перестраховываться и продолжает генерировать «Я не знаю» или «Спасибо» в большинстве контекстов, это довольно плохой бот.
Случайная выборка
В качестве альтернативы мы можем рассмотреть стохастические подходы, чтобы избежать общего ответа. Мы можем использовать вероятность каждого токена из функции softmax для генерации следующего токена.
Предположим, мы генерируем первый токен контекста «Я люблю смотреть фильмы». На рисунке ниже показана вероятность того, каким должно быть первое слово.
Рисунок 3: Вероятность каждого слова. Ось X — это индекс токена. т. е. индекс 37 соответствует слову «да». Если использовать жадный подход, будет выбран токен «i». Однако при случайной выборке токен i имеет вероятность появления около 0,2. В то же время любой токен, который имеет вероятность 0,0001, также может произойти. Просто очень маловероятно.
Случайная выборка с температурой
Случайная выборка сама по себе потенциально может случайно сгенерировать очень случайное слово. Температура используется для увеличения вероятности возможных токенов при одновременном снижении вероятности появления неверных. Обычно диапазон составляет 0 < temp ≤ 1. Обратите внимание, что при temp=1 эффект отсутствует.
Уравнение 2: Случайная выборка с температурой. Температура t используется для масштабирования значения каждого токена перед переходом в функцию softmax. Рисунок 4: Случайная выборка по сравнению со случайной выборкой с температурой
Рисунок 4: Случайная выборка по сравнению со случайной выборкой с температуройНа рисунке 4 при temp=0,5 наиболее вероятные слова, такие как i , yes , me , имеют больше шансов быть сгенерированными. В то же время это также снижает вероятность менее вероятных, хотя и не мешает им происходить.
Выборка Top-K
Выборка Top-K используется для того, чтобы гарантировать, что менее вероятные слова вообще не будут иметь шансов. Для поколения следует рассматривать только K вероятных токенов.
Рисунок 5: Распределение 3-х случайных выборок, случайных по температуре и топ-kИндекс маркера от 50 до 80 имеет небольшую вероятность, если мы используем случайную выборку с температурой = 0,5 или 1,0. При выборке top-k (K=10) у этих токенов нет шансов быть сгенерированными. Обратите внимание, что мы также можем комбинировать выборку Top-K с температурой, но вы уже поняли идею, поэтому мы решили не обсуждать ее здесь.
Этот метод выборки был принят во многих задачах последнего поколения. Его производительность довольно хороша. Одним из ограничений этого подхода является то, что в начале необходимо определить количество первых K слов. Предположим, мы выбираем K=300; однако на временном шаге декодирования модель уверена, что должно быть 10 наиболее вероятных слов. Если мы используем Top-K, это означает, что мы также рассмотрим остальные 29(p) — наименьший из возможных токенов. P(x|…) — это вероятность создания токена x с учетом предыдущих сгенерированных токенов x от 1 до i-1
Его производительность довольно хороша. Одним из ограничений этого подхода является то, что в начале необходимо определить количество первых K слов. Предположим, мы выбираем K=300; однако на временном шаге декодирования модель уверена, что должно быть 10 наиболее вероятных слов. Если мы используем Top-K, это означает, что мы также рассмотрим остальные 29(p) — наименьший из возможных токенов. P(x|…) — это вероятность создания токена x с учетом предыдущих сгенерированных токенов x от 1 до i-1
Интуиция такова, что, когда модель очень точна в отношении некоторых токенов, в противном случае набор потенциальных токенов-кандидатов невелик, будет больше потенциальных токенов-кандидатов.
Рисунок 6: Распределение выборки Top-K и ядраC ertain → эти несколько токенов имеют высокую вероятность = суммы нескольких токенов достаточно, чтобы превысить p.
Неопределенность → Многие жетоны имеют малую вероятность = сумма многих жетонов необходима, чтобы превысить p.
Сравнивая выборку ядра (p = 0,5) с выборкой top-K (K = 10), мы видим, что ядро не считает токен «вы» кандидатом . Это показывает, что он может адаптироваться к разным случаям и выбирать разное количество токенов, в отличие от выборки Top-K.
Это показывает, что он может адаптироваться к разным случаям и выбирать разное количество токенов, в отличие от выборки Top-K.
- Жадный: выбор наилучшего вероятного маркера за раз
- Лучевой поиск: выбор наилучшего вероятного ответа
- Случайная выборка: случайная на основе вероятности
- Температура: уменьшить или увеличить вероятности Выборка K (с температурой) и выборка ядра.
Мы рассмотрели список различных способов декодирования ответа. Эти методы можно применять к различным задачам генерации, например, к подписям к изображениям, переводу и созданию историй. Использование хорошей модели с плохими стратегиями декодирования или плохой модели с хорошими стратегиями декодирования недостаточно. Хороший баланс между ними может сделать генерацию намного интереснее.
Хольцман А., Байс Дж., Ду Л., Форбс М. и Чой Ю. (2020). Любопытный случай вырождения нейронного текста. В Международная конференция по обучению Представления .
Декодирование последовательности слов в архитектурах Seq2Seq
Генерация естественного языка (NLG) — это задача генерации текста.
 Задачи генерации естественного языка, такие как машина…
Задачи генерации естественного языка, такие как машина…в направлении datascience.com
Интуитивное объяснение поиска луча
Простое для понимания объяснение поиска луча
в направлении datascience.com
Две минуты НЛП — наиболее часто используемые методы декодирования языковых моделей | Фабио Кьюзано | NLPlanet
Опубликовано в
·
Чтение: 5 мин.
·
28 января 2022 г.
Photo by Aryo Yarahmadi на Unsplash страницы, такие как модель OpenAI GPT3. Результаты по генерации условного открытого языка из языковых моделей и их приложений очень впечатляют.Для генерации высококачественного текста из этих языковых моделей было предложено несколько методов декодирования. В этой статье вы увидите обзор различных стратегий декодирования: Жадный поиск , Лучевой поиск , Выборка , Выборка Top-K, и Выборка Top-p (nucleus) .
 Вы можете использовать библиотеку трансформеров Hugging Face, чтобы легко протестировать эти методы декодирования.
Вы можете использовать библиотеку трансформеров Hugging Face, чтобы легко протестировать эти методы декодирования.Жадный поиск выбирает из языковой модели слово с наибольшей вероятностью в качестве следующего слова. Предположим, что языковая модель предсказывает возможное продолжение предложения, начинающегося с «9».0057 The », выбирая из слов «
Пример вероятностей слов, предсказанных на основе языковой модели. Изображение автора.Жадный поиск всегда выбирает слово с наибольшей вероятностью, то есть « кот ».
Пример вероятностей слов, предсказанных на основе языковой модели, с выделением выбора, сделанного жадным поиском на первом временном шаге. Изображение автора.Впоследствии жадный поиск выбирает следующее слово с наибольшей вероятностью, то есть « — это ».
Пример вероятностей слов, предсказанных на основе языковой модели, с выделением выбора, сделанного жадным поиском на втором временном шаге. Изображение автора.
Изображение автора.Основным недостатком жадного поиска является то, что он не оптимален для создания предложений с высокой вероятностью, поскольку пропускает слова с высокой вероятностью, скрытые за словами с низкой вероятностью. Действительно, в нашем примере наиболее вероятно предложение « Рыжая лиса » (0,4 * 0,9 = 0,36), в отличие от « Коту 9».0058” (0,6*0,5=0,30).
Поиск луча решает эту проблему, сохраняя наиболее вероятные гипотезы (также известные как лучи ) на каждом временном шаге и в конечном итоге выбирая гипотезу, которая имеет наибольшую общую вероятность.
Предположим, мы выполняем поиск луча с помощью двух лучей. На первом временном шаге поиск луча будет рассматривать как слова « red », так и « cat », а также их вероятности.
Пример вероятностей слов, предсказанных на основе языковой модели, с выделением двух лучей, созданных поиском луча на первом временном шаге. Изображение автора.На втором временном шаге поиск луча будет рассматривать все возможные продолжения двух лучей и оставлять только два из них с наивысшей вероятностью.

- Рыжий кот : 0,4 * 0,1 = 0,01
- Рыжий лис : 0,4 * 0,9 = 0,36 (самый высокий)
- 8 :
- Кот гонит 900 * 0,2 = 0,12
- Кот пьет : 0,6 * 0,3 = 0,18
- Коту 9 лет0058 : 0,6 * 0,5 = 0,30 (второй по величине)
Таким образом, два луча на следующем временном шаге будут « Рыжая лиса » и « Кошка ».
Пример вероятностей слов, предсказанных на основе языковой модели, с выделением двух лучей, созданных поиском луча на втором временном шаге. Изображение автора.Если мы хотим закончить поиск луча здесь, нашим предсказанным результатом будет луч с наибольшей вероятностью, то есть « Рыжая лиса ».
Пример вероятностей слов, предсказанных на основе языковой модели, с выделением окончательного предсказания, сделанного поиском по лучу. Изображение автора.Было замечено, что результаты являются более беглыми по сравнению с жадным поиском, но вывод часто включает повторения одних и тех же последовательностей слов.
Простое решение состоит в том, чтобы наказывать результаты всякий раз, когда они содержат n-граммы, присутствующие в уже предсказанном тексте. Тем не менее, n-граммовые штрафы следует использовать с осторожностью. Например, сгенерированная статья о городе « Нью-Йорк» не должна использовать штраф в 2 грамма, иначе название города появится во всем тексте только один раз.
В общем, трудно настроить штрафы за n-граммы, и оказывается, что качественный человеческий язык не следует распределению следующих слов с высокой вероятностью.
Как следствие, для решения этих проблем были разработаны другие методы декодирования.
Выборка означает случайный выбор следующего слова в соответствии с условным распределением вероятности слова, извлеченным из языковой модели. Как следствие, при таком методе декодирования генерация текста не является детерминированной.
Непосредственное использование вероятностей, извлеченных из языковых моделей, часто приводит к бессвязному тексту.
 Хитрость заключается в том, чтобы сделать распределение вероятностей более четким (как при увеличении вероятности слов с высокой вероятностью и уменьшении вероятности слов с низкой вероятностью), применяя softmax к распределению вероятности и изменяя его параметр температуры , чтобы сделать его более четким или более гладкий. С этим трюком вывод обычно более связный.
Хитрость заключается в том, чтобы сделать распределение вероятностей более четким (как при увеличении вероятности слов с высокой вероятностью и уменьшении вероятности слов с низкой вероятностью), применяя softmax к распределению вероятности и изменяя его параметр температуры , чтобы сделать его более четким или более гладкий. С этим трюком вывод обычно более связный.В Топ-К , K наиболее вероятных следующих слов фильтруются, а затем следующее предсказанное слово будет выбрано только среди этих K слов.
Создаваемый текст часто звучит более человечно, чем текст, созданный другими известными методами. Одна проблема с выборкой Top-K заключается в том, что она не адаптирует динамически количество слов, отфильтрованных из распределения вероятности следующего слова, поскольку K является фиксированным. Как следствие, среди этих 9 слов могут быть выбраны очень маловероятные слова.0057 K слов, если вероятность следующего слова очень точная.

